Everyone who has worked with databases is probably familiar with relational databases, and the crown jewel of relational database management systems (RDBMS) is SQL. But over the years as data volumes have exploded, and storage & processing power with it, a new type of database also evolved along with it. A database that could collect this new and vast volume of data in its raw format and analyze it faster than traditional means. This is NoSQL. Thus the two broad categories of data can be described as SQL, or structured query language, and NoSQL, or non-structured query language. This article takes a closer look at the differences between both, and compares the two crown jewels of Amazon’s database offerings, Amazon Aurora and DynamoDB
Structure
SQL is by no means obsolete, it is still widely used and is excellent for querying relational languages, and this is the main differentiator between the two. SQL databases use fixed schemas to store data. NoSQL databases are schema-less. This can be better understood with an example, say you have to save data related to an address book. The table you will probably use will have a definite structure: say, names in one column and other parameters, like address, email id, tel number, etc in different rows. Now say you suddenly need to add a row for hobbies; this is not possible, as there is no row defined for this in the schema. And this is where schema-less tables score over SQL. In a similar use case as the one described for SQL, you do not need to add a predefined schema for the new information. Each row is simply a repository for different information. So, for example, you can have the name, age, hobbies, and email in the first one, and name, sex, address, and telephone number in the next. Each one can hold different information. So the biggest difference between SQL and NoSQL is that the former is structured to have a defined schema and the second is schema-less and holds unstructured data. Note here that a NoSQL database can also hold structured data.
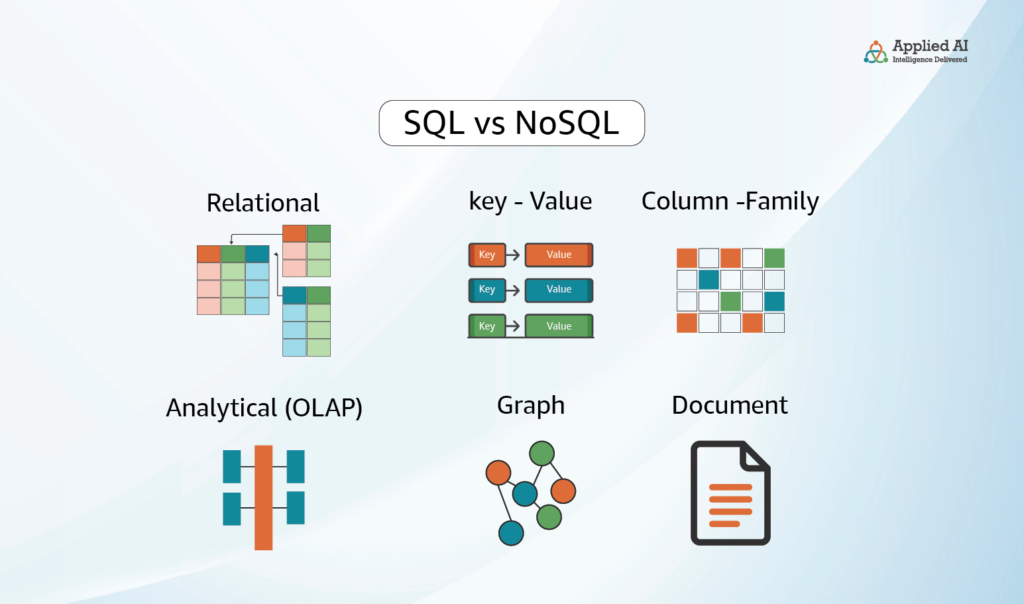
Types of NoSQL databases
There are four basic NoSQL types of databases: document databases, key-value databases, wide-column stores, and graph databases.
Document databases store data in documents, like JSON files, containing pairs of fields and values. Values can be objects, numbers, booleans, or arrays. Key-value databases store data in keys and values. Wide column types store data in tables, rows, and dynamic columns. Lastly, Graph databases store data in nodes, which can be information about people, places, things, etc, and edges, which store information about relationships between the nodes.
Schema vs Schema-less Pros and Cons
The big advantage of SQL databases and their predefined schema is that the data is better set up. The indexes, secondary indexes, foreign keys, are optimized and The database already understands the columns and rows and what is where, so it is easier to query. Thus, SQL databases are good for joints and complex queries, like those involving multiple tables. As there are predefined columns, foreign keys that the database understands, you can link an SQL database to multiple tables, so you can join tables and run sub-queries, etc. Schema-less NoSQL databases have different data for every item or row making it impossible to define the different keys that the NoSQL database supports. And the absence of a predetermined structure makes it unsuitable for complex multi-table queries.

Transaction Processing
In terms of processing transactions, SQL databases follow the ACID principles, where A-C-I-D is an acronym for:
Atomicity: where changes are performed in unity or not at all
Consistency: from the time a transaction starts till it ends, the data state is consistent
Isolation: the intermediate status of a transaction is invisible to other transactions
Durability: changes to data remain even if there is a system failure
NoSQL databases follow CAP or the CAP principle, which refers to
Consistency: when the nodes have the same data item and every node returns the same after a successful write. It implies that every client gets the same view of the data
Availability: when the system sends a successful/unsuccessful message after every read/write operation is completed
Partition tolerance: means the system continues operating even if connecting nodes in the network have a fault

Amazon Databases
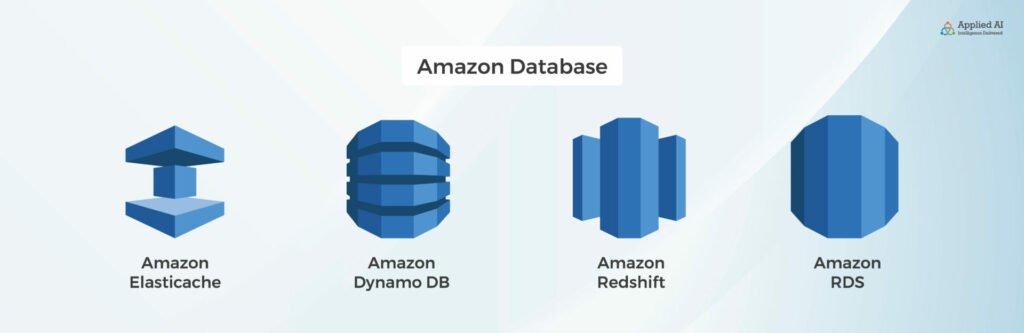
AWS offers a choice of both types of databases. In SQL, you have Amazon Aurora and Amazon RDS; Amazon DynamoDB, Amazon DocumentDB (which is compatible with MongoDB), and Amazon Managed Apache Cassandra Service. But AWS also allows you to run any database you might prefer on EC2, although it is recommended that you pick one of AWS’s native databases preferably.

Vertical Scaling vs Horizontal Scaling
Amazon Aurora
Amazon Aurora is Amazon’s premier SQL database. It was released in 2015, and is based on the Relational Database Management System (RDBMS) model. It is a different beast than SQL but it supports SQL language. It is compatible with MySQL and PostgreSQL, but much faster than both.
Amazon Aurora uses a concept called Referential Integrity, which doesn’t use Foreign Keys. Referential Integrity requires that the values in the foreign key column must be present in the primary key that is referenced by the foreign key or the values must be null. This ensures the data in the database remains consistent. It keeps incorrect records from being added, deleted, or modified.
Where DR is concerned, Aurora allows backups and snapshots
To ensure high availability for your Amazon Aurora Database you can choose multiple AZs and read replicas.
Scaling in Amazon Aurora happens vertically. This means choosing a bigger/more powerful server, i.e. EC2. Although Serverless Aurora scales automatically.
Amazon DynamoDB
DynamoDB is a proprietary database developed by Amazon in 2012. It is a fully managed, scalable database service built for the cloud. Unlike Aurora it doesn’t use the concept of Referential Integrity; so, there is no Foreign Keys DynamoDB’s primary database model is a document store and a key-value store.
As with most NoSQL databases, it doesn’t support SQL query language; Unlike Aurora, which only supports the Master-Slave replication method, DynamoDB supports most replication methods.
It supports cross-region replication. This means that if you have a table in US East one, which is replicated in US West two, you can insert a row in either one of the tables, it will be instantly replicated in the other
It is highly available and resilient as it instantly replicates across three AZs.
DynamoDB scales horizontally. This means it spins out multiple read replicas to handle spikes in traffic. It can handle more than 10 trillion requests/day with peaks of more than 20 million/second. This makes it much more scalable than Aurora, although Serverless Aurora does scale automatically, it is not as scalable as DynamoDB
DynamoDB is inherently durable, enabling Point in Time Backups.
Choosing the ideal database doesn’t mean picking one or the other. Rather it’s a matter of picking the right tool for the job. For instance, say you’re in charge of a project and you choose to work with a NoSQL database. This doesn’t mean you have to force-fit everything to the NoSQL database, even if it would be a better match for SQL. With most modern applications being Microservices-based, the choice becomes easier, because microservices architectures are autonomous, in that you can pick SQL or NoSQL database, whatever fits the solution better. At the end of the day, the choice is not between SQL and NoSQL or Aurora vs DynamoDB but the actual case, performance levels, and cost requirements.