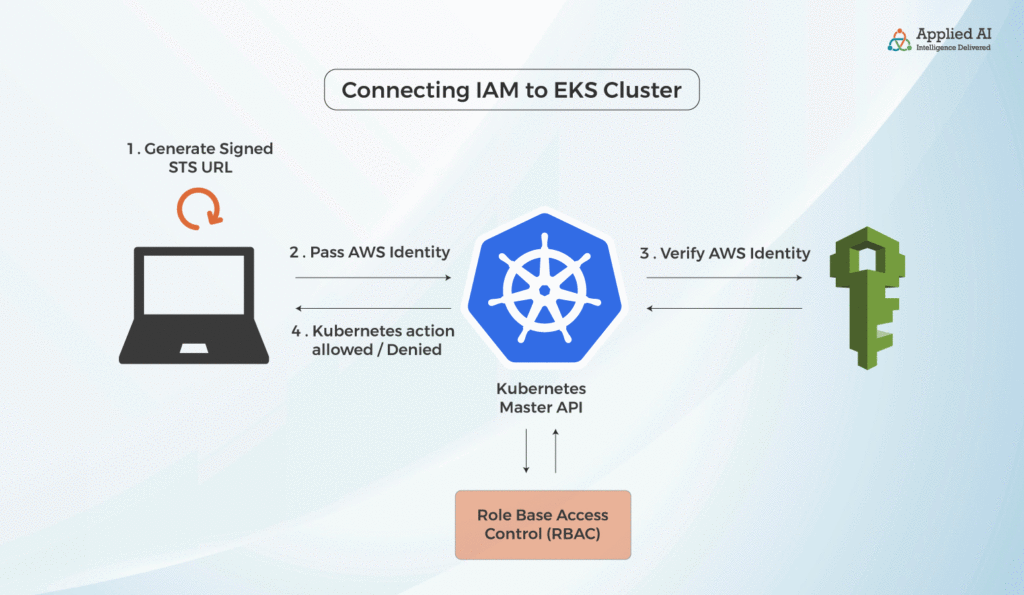
Kubernetes’ API only responds to requests that it can authenticate. This means that in order to properly secure your Kubernetes API, you need to secure your Role Based Access Control (RBAC) policies. RBAC is basically a mechanism that allows access to only users, i.e. as per permissions that have been set by you as admin. So how do you secure your application running on Kubernetes in AWS?
Let’s begin by revisiting the basics. Your application is running in a pot and to function properly you need to give the pod access to AWS resources, like creating a load balancer or attaching security groups. If your application were running in a standard Amazon EC2 instance you would simply attach IAM (Identity & Access Management) roles with policies allowing certain actions (for example, the ones mentioned above). Now since the pod is running in Kubernetes, you can’t simply attach an AWS-specific service like IAM, instead, you need to go back to the source, i.e. the Deployment Manifest. But the Deployment Manifest, too, is a Kubernetes construct, and as we noted, you can’t simply attach AWS cloud-specific constructs like IAM. Rather, we need to abstract such cloud-specific constructs. This will allow Kubernetes to run in other cloud platforms—AWS, in this case. This simply means inserting a layer in between…i.e. Service Account.
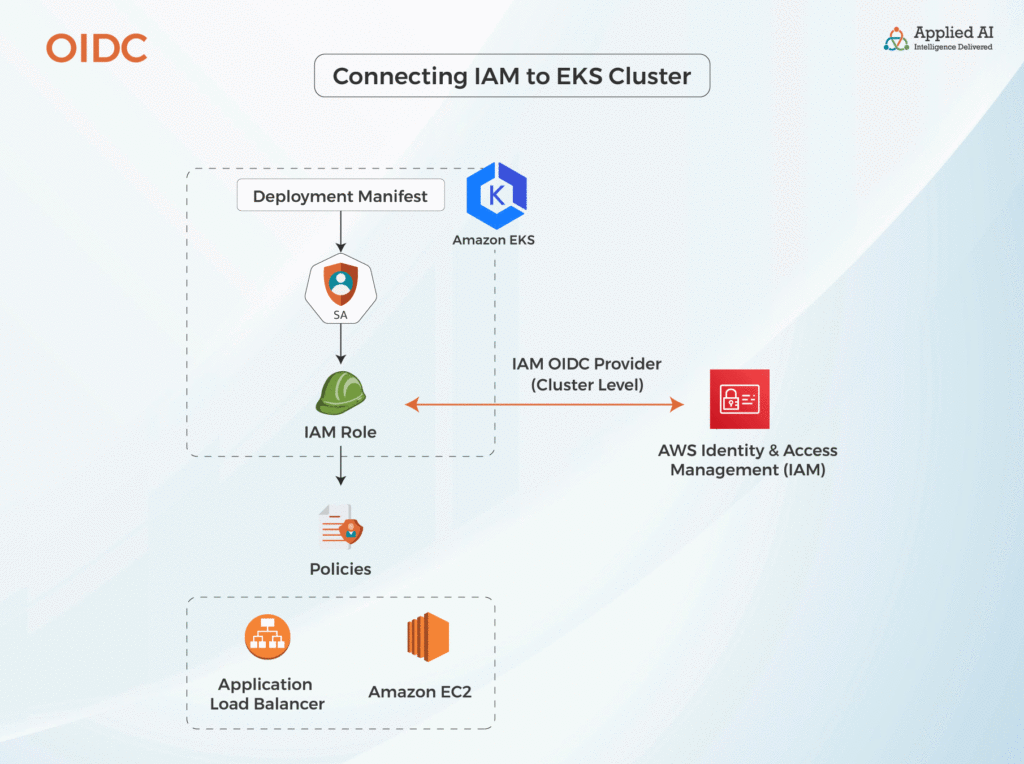
In a nutshell, the stack goes something like this: policies that allow access to resources that you specify. These policies will be attached to an IAM role, and this IAM role is attached to Service Account—which is a Kubernetes construct—and finally, this Service Account is connected to the Deployment Manifest. Since the Deployment Manifest-Service Account is running in AWS EKS, it needs a way to connect with AWS IAM service to validate the permissions and policies you have set. So what we do is use an IAM OpenID Connect (OIDC) service—an authentication protocol—to connect your policies to your cluster. This is set up at the cluster level, and only needs to be set up once.
Now, if you run “cubectl get sa account” you will get “default‘ in return; however if you run cubectl sa -A (A in Capital) it returns a list of all the Service Accounts in your Kubernetes cluster. For the purposes of this article, we will pick alb ingress controller. The alb ingress controller monitors ingress and interacts with the Kubernetes API server. When the ingress resource is deployed, it allows you to create Application Load Balancer Security groups, attach a Security Group, etc. The IAM Role associated with each Service Account is connected to a role name and in you look up the role name you can see all the policies connected with that role, e.g. EC2 security group, role to create load balancers, etc. Remember, the Service Account is attached to an IAM Role, and has nothing to do with the Kubernetes cluster or the pods in which your application is running. Now the pods—which are running the application need access to the Kubernetes cluster. This is where ClusterRole comes in.
Role & ClusterRole
Just as an IAM Role gives access to specific AWS resources, ClusterRoles give the pods access to resources on a cluster level. The roles allow you to create/delete/list on the nodes, pods, namespaces, and all other resources you need on a cluster level to run your application effectively in the pod. In other words, to run your application effectively you need access to both AWS resources as well as Kubernetes cluster resources. ClusterRole gives you access across the cluster; if you have Admin-level access you can do just about anything, which is why Admin ClusterRoles should only be used with caution.
Role binding grants permissions as defined in the role to a user. Permissions can be within a namespace or cluster-wide, the former is known as RoleBinding, and the latter, ClusterRoleBinding.
If you look at a typical manifest file, at the bottom you can see information about the Service Account creates, the name of the Service Account, and in which namespace it has been created. Above this, you can see the ClusterRole that has been created, under ‘Rules’ you can see which resources it has access to and the kind of actions this ClusterRole can take. To connect this ClusterRole with the Service Account, you have ClusterRolebinding in the center layer. The ClusterRole is referenced with the name specified.
ClusterRoles are reusable, i.e. they can be replicated for another namespace. All you need to do is create a Service Account in that specific namespace and reference the same ClusterRole to that Service Account.
Role is not an IAM construct, it is a Kubernetes term.
Both ClusterRole and role represent permissions. These are similar for both role and ClusterRole but role defines permissions with a specific, defined namespace, and works only on resources—such as pod, replicaset, and cluster—specific to that namespace.
ClusterRole, on the other hand, defines permissions across the cluster, i.e. not specific to a particular namespace. In a nutshell, if you put a namespace when you define a role it becomes a regular role; if you don’t put a namespace when defining the role, you’re not tying it to any specific namespace and it becomes a ClusterRole.
Role Based Access Control (RBAC)
There are two basic areas to secure in a Kubernetes application: one is your application’s security, and the second is security for you as the user. ClusterRole, Service Account, Role Binding, etc all were aspects to secure your application. Security for the human user consists of granular permission specific to the user type. For instance, for a DevOps person, you’d want to grant permissions, like give, create, get, and list, in a particular namespace or on deployments, replicasets, and pods. To do this, you will first create the Kubernetes role defining access to resources in that namespace. (This is a namespace-specific Role). Then you will map that Kubernetes username to the Role using RoleBinding. Finally, you need to map the AWS IAM username to the Kubernetes username and group using Configmap/AWS auth. Both Rules and ClusterRules are similar, so you can define API groups, resources verbs, etc.
You can have two namespaces running in the same node (or EC2 instance), with different pods, and each namespace running a different application. You can create a Service Account for each of the namespaces, tie each to an IAM Role and connect that to a cluster role specific to the corresponding namespace. Now each of the IAM Roles and Cluster Roles in the two namespaces can have totally different permissions and access, even though they are running in the same node/EC2. The reason for this is that if you put an IAM role associated with a particular node that has access to all the pods, you are, in effect granting permissions to all the pods running in that node.
Finally, please note that this concept is only available from Kubernetes version 1.14 onwards; it replaces Cube2IAM.