AWS offers such a vast array of services that it can be a little daunting to comprehend the full ecosystem. There are more than 130 different services and they span the full gamut of computing, including services for compute, analytics, storage, developer tools, security, and more. This article seeks to show you the structure behind the services. Rather than explain what each service is and what it does, we’ll understand the services by referencing them in the context of a typical architecture.
Ready? Let’s dive right in.
What does AWS do?
At its most fundamental level, AWS is a company that owns and operates data centers all over the world. Let’s understand the structure of these data centers.
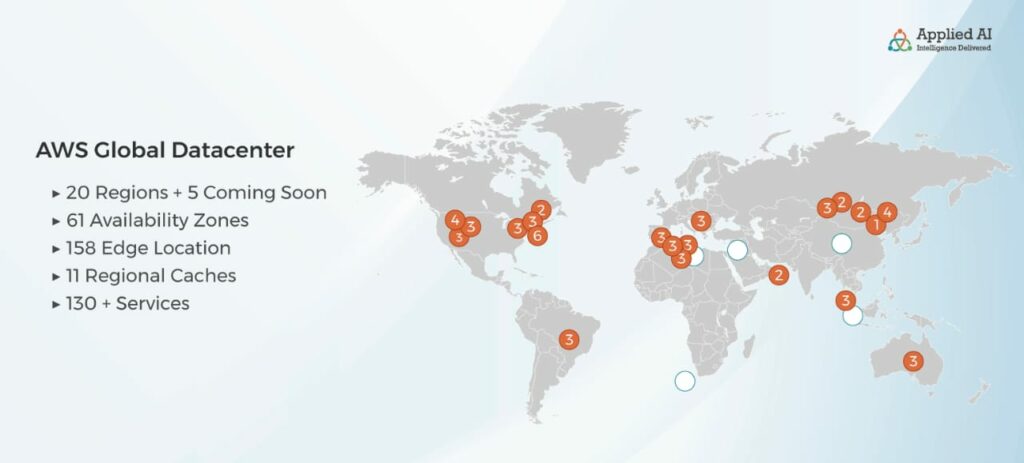
At the global level are the AWS Regions. There are 20 such regions (with five more coming up soon) and they are located across the world, some in North America, a few in Europe, a few in Asia, etc. Each region comprises two or more Availability Zones (AZ), which are basically data centers. The name indicates their purpose. i.e. enabling availability. Typically, users have their workloads running in two or more AZs. This ensures that even if one goes down for any reason, your applications will still have high availability
AWS also has something called Edge Locations. There are present across 100+ cities. These are used to cache and deliver content directly to the user from the nearest location. This reduces latency considerably
Regions, AZs, and Services
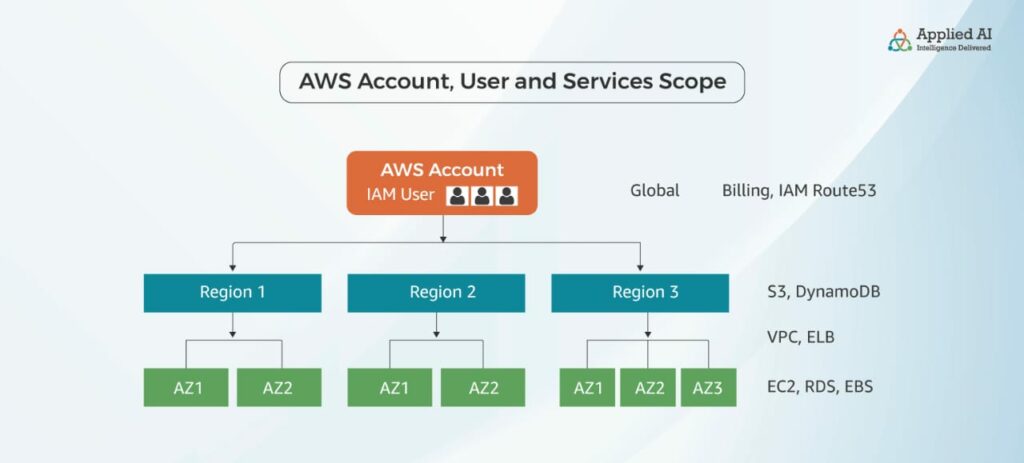
To understand how these regions and services correspond to each other, think of the entire ecosystem as a hierarchy. At the top, you have the AWS Account. Your AWS Account allows you to deploy your infrastructure across AWS regions. At the account level, you have the billing services, and you also have IAM, which is AWS’s Identity and Access Management service. It allows you to create user/user groups, assign roles, permissions, etc. Because this is at the Account level, they would have access to all the Regions within your account (as per their permissions). Below this, you have the Regions. At this level, you can work with services like S3, and DynamoDB. When you create an S3 bucket you also have to select the region where your bucket will operate. The same thing applies to DynamoDb.
Next comes the AZ level. The scope of services here includes EC2—the core building block of AWS’s infrastructure—RDS databases, and Elastic Block Storage (EBS). Since the scope of these services is limited to the AZ level, you cannot have, for instance, an EC2 instance (which is basically a virtual machine running in another AZ at the same time.
AWS Services
As we saw, there are 130 different AWS services, and they can be broadly categorized as Compute (ECS, Autoscaling, Lambda Load Balancers) Data Storage, Data Analytics, Container Services, Network services, App Development tools, Management, and, of course, Security.
So, let’s see how these services come into play in a typical AWS cloud architecture.
For the purposes of this article, we are going to build a hypothetical application with the architecture it needs to run. The application will be a hypothetical Social Media website—a kind of Instagram or Facebook. Let’s call it iG2.com.
Finally, we will map the various AWS services to the different components in our architecture.
To begin with, we will deploy this application in our on-prem data center. To ensure security, we will need a private network. We will require an application server or web server. Users will access this application using our IP address initially. Now, over time, we will want to extend the application and add some business logic, and functions like log-in, etc. So we will put in a web server, as well.
Next, we need some kind of database, a relational database is the best bet, so we will put in a MySQL database. Now we have a 3-tier architecture and it’s doing fine. But as traffic grows, the webservers or application servers become a bottleneck, which means we need to scale. Typically 3-tier architectures are scaled horizontally, so we bring in multiple web servers, which means multiple IP addresses, then we put in a load balancer that will distribute traffic to the multiple back-end servers. Now we want our users to access the application through the domain name ig2.com so we need a DNS service using which the domain name is mapped to the load balancer.
As usage grows so does the data generated and the original database is unable to keep up with the diverse data and volume. Since we need a scalable database that can store various types of data without restriction, we pick a NoSQL database. To ensure the database doesn’t become a bottleneck, we put in a database cache engine. This way we can query the data without the application servers hitting the database, as the cache engine will serve all requests. Now since this is a social media website for sharing images and videos, countless pictures and videos will be uploaded every day, and the disc attached to the VM, having limitations, can’t scale on the fly. This means we need some unlimited storage solutions like a file storage solution or shared filesystem, preferably external, something like Google Drive. Now, some of the videos and images may contain vulgar or objectionable content, which needs to be filtered out as soon as the images/videos are uploaded, and stored elsewhere. So we need a content filter.
This application uses advertising as a revenue source, which means showing ads related to individual users’ content consumption patterns. What they like, what they click on, etc. So the application has to watch users’ actions, map likes and dislikes, and, based on the data, show relevant ads. This is known as clickstream analysis. As each click is analyzed we can get insights into trends. All this data has to be stored in a place from where you can run further data operations, which calls for a kind of Hadoop platform. You will also need a data warehouse. So let’s put that in, as well. Since this is the 21st century it is more than likely that your users are accessing the application using mobile devices. So now we need to have the videos in different formats suitable for viewing on different devices. This job can be done by a video converter. Whenever a user uploads a video, it is immediately converted into a mobile-friendly format.
Sometimes a video goes viral. When this happens the traffic to the external hard drive will be too much for it to handle. To ease the load we use a Content Delivery Network (CDN). These are simply caching devices located as close to the user group as possible. The content is then served up to the user from the nearest location, not necessarily the original. This improves performance and lowers latency. The next feature we need to add to the application is the ability to send notifications, for example, there’s a new post or message from a friend of one of the users. So we need to add a service for this functionality as well. This should also include the ability to message friends. We can use a queue service like RabbitMQ or IBM MQ for this. Finally, we have to monitor our architecture to know how the VMs, databases, storage, etc. are functioning. So we need a monitoring and dashboarding service. This then is how the architecture would look if it were deployed on-premises. Now if we were to deploy the same thing on AWS to take advantage of the many benefits that the cloud offers, like pay-as-you-go, elastic scaling, etc, here’s what it would look like.
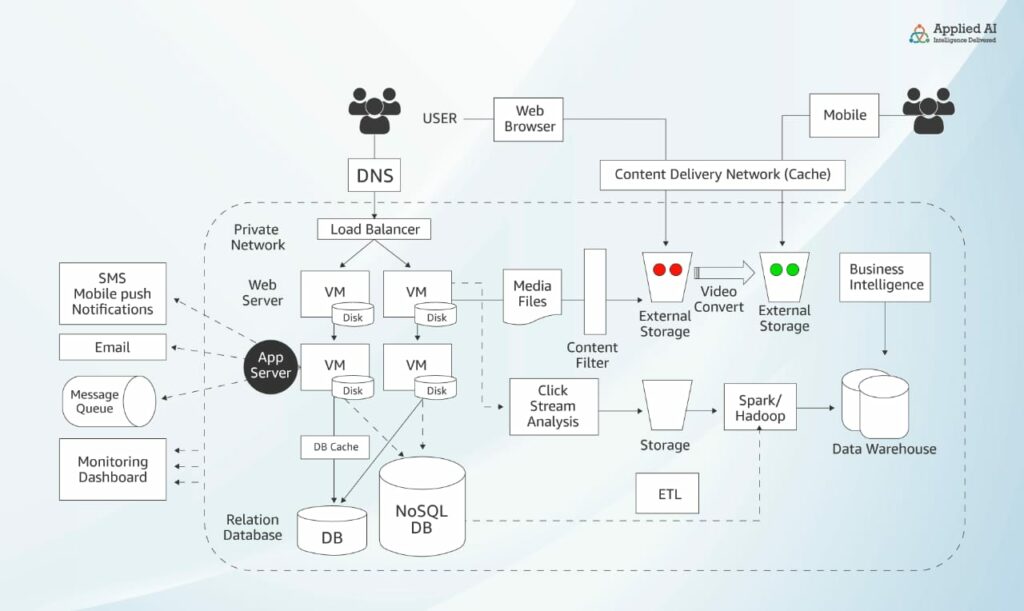
Services in a typical on-premises architecture
The private network would be a Virtual Private Cloud (VPC) which AWS provides. This will be the base for our application and architecture.
The VM, in the AWS cloud, would be EC2 instances and their attached disks, Elastic Block Storage (EBS). You can incorporate auto-scaling for the EC2, so if traffic increases a new VM will automatically be spun up, i.e. horizontal scaling. If traffic decreases, they can reduce the VMs automatically. The relational database in AWS is RDS, and an AWS service known as DynamoDB is a NoSQL database. The database caching service is called ElastiCache and it comes with a Redis and Memory cached engine. The load balancer in AWS’s world is a service known as Elastic Load Balancer (ELB). This ELB takes care of distributing incoming requests among your back-end EC2 instances. The DNS service gets replaced with Amazon’s Route53.
For external storage—remember Google Drive?—it becomes Amazon’s Simple Storage Service (S3). S3 is an unlimited storage service, and it is accessible directly over the internet. For the content filter, we use AWS Rekognition, which filters our objectionable material before content reaches the S3 buckets. For seamless video conversion into a mobile-ready format, we use AWS’s Lambda service. Lambda is a serverless service. You just code the video conversion steps and it gets triggered and executed as a Lambda function whenever a video is uploaded. This is a serverless service so there is no server to manage and it scales automatically. Clickstream analysis is done by an AWS service called Kinesis. Kinesis collects the data and stores it in S3 for further analysis. The Hadoop platform becomes a managed service called EMR and it runs operations like aggregation, sorting, and running distributed jobs like SPARC and Flink.
Let’s not forget the DynamoDB data. You can run Extract Load Transform operations using EMR with a service known as Amazon Glue. All this data can be stored in the data warehouse, which is nothing but Amazon Redshift. Redshift can store massive data volumes…on a petabyte scale. Data analysis can be performed on this data using Amazon Quicksight or Athena (an SQL query engine). Quicksight also allows you to build graphs and charts to help deliver insight for your business decision.
The content delivery network is Amazon CloudFront, which stores your cached data in Edge locations in 100+ cities across the world. So users from a particular location are served content from the edge location nearest to them. For messaging and push notifications Amazon provides a Simple Notification Service, or you can send emails/bulk email using Simple Email Service (SES), or chat using Amazon’s Simple Queue Service (SQS). Monitoring your AWS cloud is done by an Amazon Service called CloudWatch. It also allows you to set alarms that get triggered by preset situations—say, your CPU utilization goes beyond a set percentage. In such instances, an alert is sent to the administrator, so they can take appropriate action.
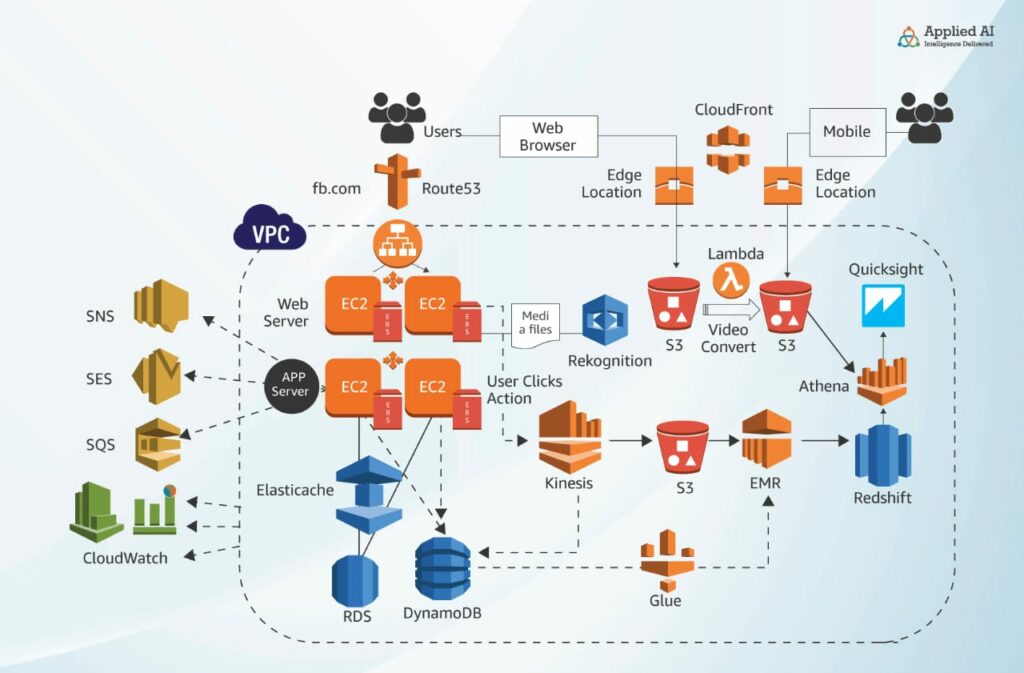
Services in an AWS architecture
Now, what happens when you need to expose your application using API calls to allow a third-party application to integrate with your application? In Amazon, this is taken care of by API Gateways. All you need to do is write the code defining your API and deploy it in the API Gateway.
Security in AWS
The top level of security to manage all access is managed by AWS Identity and Access Management (IAM) It is the premier service to secure your AWS account and all your services. In addition to this, you can encrypt your data, which may be stored in EBS, S3, EMR, Redshift, and databases, using Amazon KMS (Key Management Service). This eliminates the need for a separate secure location to store your keys and perform encryptions. SSL certificates are managed by Amazon Certificate Manager ACM. Finally, you can deploy web application firewalls (WAF) in front of your API Gateway, and in CloudFront and your Load Balancers to prevent cross-site scripting, DDoS attacks, etc.
This is by no means the complete list of AWS Services, but these are the most commonly used services. If you’d like to know more about a specific service, let us know in the comments below.