Serverless computing and microservices have a lot in common; both seriously disrupted computing as we know it, both offer excellent scalability, both are cloud based, both are modular in nature, and both help minimize overheads. So are they made for each other? Let’s take a closer look.
Serverless computing describes an approach that abstracts away the server infrastructure relieving developers of the necessity to provision, manage and secure the underlying infrastructure needed to execute code. Serverless computing is best applied in executing smaller segments of code, which are triggered by pre-set events. They are also modular in nature and easy to automatically scale, making them ideal for use in microservices based architecture.
Microservices architecture arose in response to the difficulty—and expense—in managing traditional monolithic applications, which are designed as one integrated and independent unit, i.e. database, client-side interface, and server-side interface all compacted in one unit. Monolithic applications are fairly rigid, making them difficult to scale, update, and manage, except as simple applications.
Unlike monolithic applications that are built as one integrated unit, microservices comprise smaller services—each handling only one service, managed independently, and individually scalable.
For a deeper understanding, read: Monolithic vs microservices: principles and practices
For instance: an eCommerce website built as a microservices application would contain individual microservices for aspects like product catalog, check out, shipping, et al. These microservices can be hosted on containers, VMs, or private clouds. Their modular nature makes them easy to scale horizontally; where, in the event of a peak, monolithic applications would have to be scaled up in entirety, in microservices-based applications, only the service that’s facing the rising demand can be scaled.
Serverless microservices: how it works
Since a microservice may comprise just one or two functions—that are concurrently deployed—each microservice can be broken down to individual functions and hosted on serverless. The serverless function will execute the corresponding code in response to a pre-set trigger: http request, file download or upload, or any other event.
Continuing the above example: when an order is ready to ship, it could trigger a function that checks and confirms the shipping address, this, in turn, could trigger another function that handles printing of a shipping label, and trigger another function, which could send a shipment notification to the intended recipient. This is a fairly simple explanation; in actual implementation one would add things like queues in between for fail safe and to manage the parallel processing limits of the serverless infra as well as the system needs.
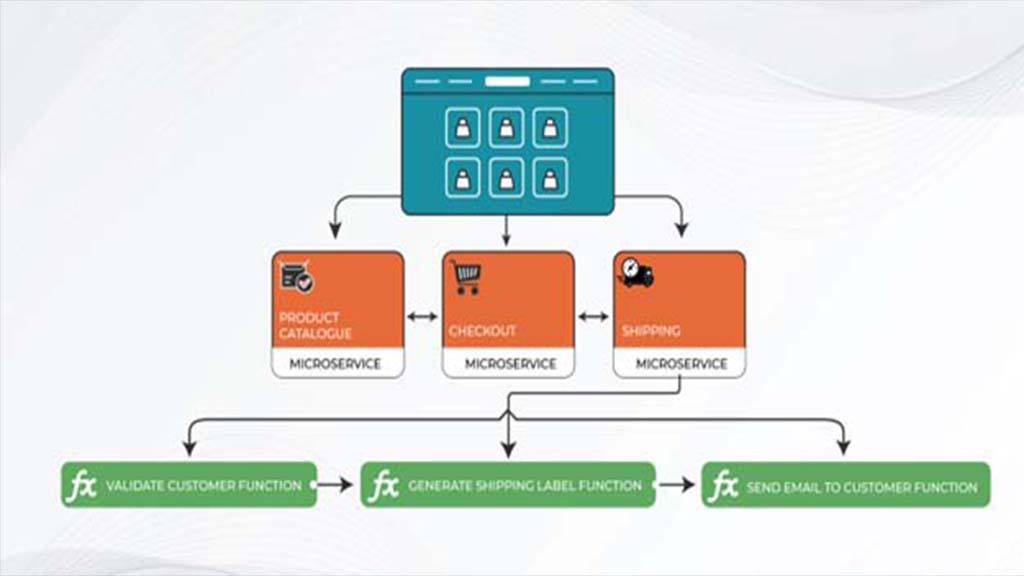
Typical Serverless Microservice-based Architecture
Benefits of serverless microservices
Broadly, serverless microservices offer all the advantages that serverless architectures provide, such as:
- Lower overheads, possibly lower than container based microservices.
- Cost-efficiency—you avoid the cost of provisioning and managing underlying infrastructure, and only pay for what you actually use. i.e.only when the function is called.
- Easy scalability—their modularity makes horizontal scaling simple
- Manageability—thanks to their modularity
- Flexibility: This means that functions used in one microservice can also be extended to other microservice—if it uses the same logic and components. This reduces the amount of code that would otherwise have needed to be written to scale out the application

Use Cases:
Any evolving application, especially the complex ones, make good candidates for serverless microservices: their modularity makes them simpler to manage and scale.
If the application can be broken down into multiple, disparate services, and each, in turn, can be split into short, event-driven tasks. Applications that handle consistent loads (i.e. requiring them to be constantly ‘on and being used’, or those that handle long running tasks, would work better as monolithic applications.
Challenges
While serverless microservices allow quick and cost-effective iteration, they do pose a few challenges
- Defining function boundaries. It’s important that each function has a limited role, but it’s not easy to define the scope of each function, furthermore stretching your logic across too many functions makes it harder to add updates or add new features.
- Cold starts. When and if a function is triggered after a period of inactivity, it can cause higher latency. This can be resolved by keeping those functions ‘warm’. This can raise costs but, depending on the application, can still be more cost effective than a monolithic approach
- Complex troubleshooting. One application typically comprises multiple microservices, each of which use functions that are short liven and shares with other resources. This complexity makes it difficult to understand dependencies and trace root cause of errors is they arise.
These challenges can be resolved by a) keeping the occasionally needed functions in a warm mode—for instance, the service handling sign-in or account creation, and b) by migrating to serverless in reverse-priority, i.e. moving non-critical microservices to serverless first.
In a nutshell
Serverless microservices refers to cloud-based services that use serverless functions to perform specific tasks within an application. Serverless functions are modular and, thus, easily scalable, rendering them ideal for microservices-based architecture. This approach combines the benefits of serverless computing and microservices architectures, enabling lower costs, lower downtime, higher scalability, and independent deployment. As with any computing technology, serverless microservices is not a one-size-fits-all solution. Simpler applications, and those with long running services, are more suited for a monolithic design.